I’ve recently been setting up and resetting several machines. One task in my setup list is to get my custom Edge search engines configured. Unfortunately, Edge does not synchronize custom search engines as part of profile data (Chrome does). But I synchronize this data myself.
What’s a Custom Search Engine?
Edge and Chrome both support configuring keywords that give you shortcuts to perform searches on websites. Many websites register their own search engines while you browse them, but you can also define your own using a URL template.
You can see the search engines defined within your Edge profile by going to edge://settings/searchEngines. This is found by navigating to Settings > Privacy, search, and services > [Services] Address bar and search > Manage search engines. Edge installs Bing, Google, and Yahoo as defaults; I personally use DuckDuckGo as my default search engine (which Edge also sets up for me). Reviewing these, you can observe a URL template where %s is used as the search term placeholder.
Each address bar search engine has a “Shortcut” defined, which is the keyword you type at the beginning of an address bar search to invoke that search engine. For example, bing.com is the Shortcut to use Bing–if you type "bing.com edge custom search engines" into your address bar, you’ll see Bing recognized as the search engine as soon as you hit the space after “bing.com”.
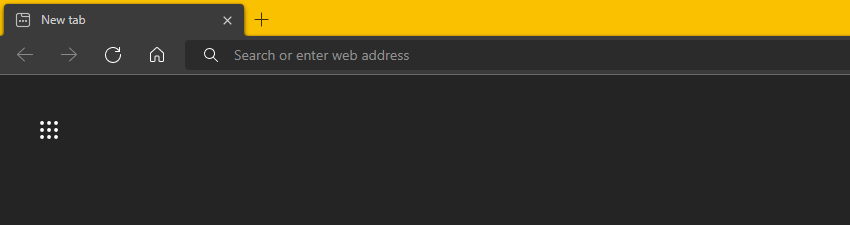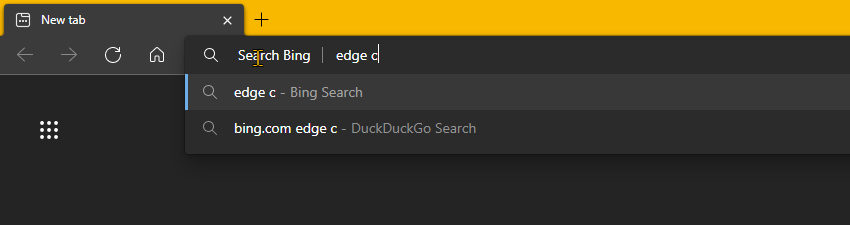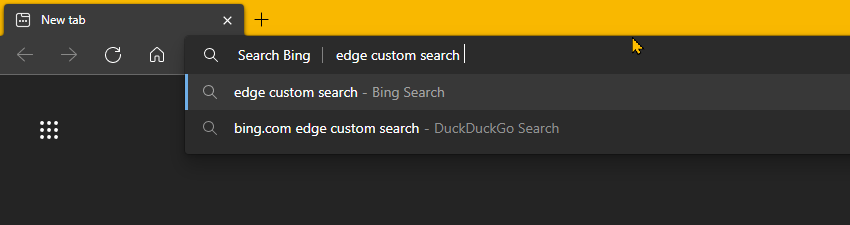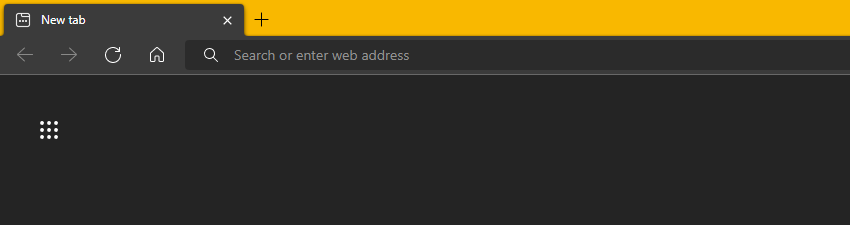
From this settings screen, you can add your own custom search engines using the Add button. The Search engine is the friendly name, the Shortcut is the keyword you type into the address bar to invoke the search engine, and then there’s a field for entering the URL template. As the field label explains, enter a “URL with %s in place of the query”.
My Work Search Engines
In my Edge profile for work, I have quite a few search engines registered. These search engines help me navigate our team’s issues and pull requests and quickly pull up .NET API reference documents.
| Search Engine | Shortcut | URL Template |
|---|---|---|
| .NET API | api | https://docs.microsoft.com/en-us/dotnet/api/?term=%s |
| dotnet org | dotnet | https://github.com/dotnet/%s |
| runtime repo | runtime | https://github.com/dotnet/runtime/%s |
| analyzers repo | analyzers | https://github.com/dotnet/roslyn-analyzers/%s |
| runtime: tree | tree | https://github.com/dotnet/runtime/tree/%s |
| runtime: pulls | pulls | https://github.com/dotnet/runtime/pulls/%s |
| issuesof.net | issuesof | https://issuesof.net/?q=is%3Aopen%20is%3Aissue%20%s |
| runtime: issue by id | issue | https://github.com/dotnet/runtime/issues/%s |
| runtime: issues by area | area | https://github.com/dotnet/runtime/issues?q=is%3Aissue+is%3Aopen+label%3Aarea-%s |
| GitHub Fork | fork | https://github.com/jeffhandley/%s |
api- search the dotnet API documentation for a type or member name; e.g.api ValidationContextdotnet- navigate to a dotnet org repository on GitHub; e.g.dotnet command-line-apiruntime- navigate to a URL within the dotnet/runtime repository on GitHub; e.g.runtime issuesanalyzers- navigate to a URL within the dotnet/roslyn-analyzers repository; e.g.analyzers pulls/jeffhandleytree- navigate to a branch’s tree within the dotnet/runtime repository; e.g.tree mainpulls- navigate to a contributor’s pull requests in dotnet/runtime; e.g.pulls jeffhandleyissuesof- search for issues matching a search term, using issuesof.net; e.g.issuesof BinaryFormatterissue- navigate to an issue within dotnet/runtime; e.g.issue 71496(bonus:issue jeffhandleyis also recognized, loading issues authored by ‘jeffhandley’)area- load open issues in dotnet/runtime with a specific area label; e.g.area System.Text.Jsonfork- navigate to one of my GitHub repos/forks; e.g.fork runtime
Synchronizing Search Engines
UPDATE: MARCH 2025 – THIS APPROACH NO LONGER WORKS. THERE ARE ADDITIONAL FIELDS ADDED TO THE SCHEMA, INCLUDING A HASH COLUMN. WHEN THE VALUES ARE NOT VALIDATED, THE ROW IS DELETED FROM THE TABLE WHEN EDGE LAUNCHES. I AM TRYING TO SOLIDIFY A PROCESS THAT STILL USES DB BROWSER FOR SQLITE TO EXPORT THE keywords TABLE FROM ONE MACHINE TO A SQL FILE, AND THEN IMPORT THAT ON ANOTHER MACHINE. I DON’T HAVE THE PROCESS FULLY FIGURED OUT YET THOUGH.
OK, I kind of lied. I don’t really synchronize my search engines. But I keep the above search engine definitions saved in a handy format for loading into an Edge profile.
Edge stores these custom search engines (and a lot of other settings) in a SQLite database. When all msedge processes have been killed, you can load that database, browse its schema/data, and execute SQL statements against it. You can export data and import data too, but I’ve found that to be less dependable since the schema changes from time to time. I have the following SQL file saved in OneDrive so that I can get to it quickly after setting up a machine.
INSERT INTO keywords (id, short_name, keyword, favicon_url, url, safe_for_autoreplace)
SELECT 50, ".NET API", "api", "https://docs.microsoft.com/favicon.ico", "https://docs.microsoft.com/en-us/dotnet/api/?term={searchTerms}", 0
UNION ALL SELECT 101, "dotnet org", "dotnet", "https://github.githubassets.com/favicons/favicon.svg", "https://github.com/dotnet/{searchTerms}", 0
UNION ALL SELECT 102, "runtime repo", "runtime", "https://github.githubassets.com/favicons/favicon.svg", "https://github.com/dotnet/runtime/{searchTerms}", 0
UNION ALL SELECT 103, "analyzers repo", "analyzers", "https://github.githubassets.com/favicons/favicon.svg", "https://github.com/dotnet/roslyn-analyzers/{searchTerms}", 0
UNION ALL SELECT 111, "runtime: tree", "tree", "https://github.githubassets.com/favicons/favicon.svg", "https://github.com/dotnet/runtime/tree/{searchTerms}", 0
UNION ALL SELECT 120, "runtime: pulls", "pulls", "https://github.githubassets.com/favicons/favicon.svg", "https://github.com/dotnet/runtime/pulls/{searchTerms}", 0
UNION ALL SELECT 130, "issuesof.net", "issuesof", "https://issuesof.net/favicon.png", "https://issuesof.net/?q=is%3Aopen%20is%3Aissue%20{searchTerms}", 0
UNION ALL SELECT 131, "runtime: issue by id", "issue", "https://github.githubassets.com/favicons/favicon.svg", "https://github.com/dotnet/runtime/issues/{searchTerms}", 0
UNION ALL SELECT 132, "runtime: issues by area", "area", "https://github.githubassets.com/favicons/favicon.svg", "https://github.com/dotnet/runtime/issues?q=is%3Aissue+is%3Aopen+label%3Aarea-{searchTerms}", 0
UNION ALL SELECT 150, "GitHub Fork", "fork", "https://github.githubassets.com/favicons/favicon.svg", "https://github.com/jeffhandley/{searchTerms}", 0
There are a few things to note with this data:
- Instead of
%s, Edge stores the URL templates using{searchTerms} - The
idcolumn is the unique key for the search engines, and it dictates sort order in the settings UI - Icons can be specified
- There’s a field for
safe_for_autoreplace; I’m not sure what it does, but I noticed custom search engines I configured through the UI all had0as the value, so I apply that
Editing Edge’s SQLite database
The database file can be found at %LocalAppData%\Microsoft\Edge\User Data\{ProfileName}\Web Data. The default profile name is "Default", and then each profile created after that is saved as "Profile 1", "Profile 2", etc. Note that Web Data is an extensionless file, not a folder.
To open and edit this SQLite database, I use DB Browser for SQLite. I use the portable app so that I don’t have to install it on each machine; I just carry it in OneDrive next to my search engines SQL file. Once you launch it, open the database by navigating to the Edge profile folder. You’ll need to change the file types drop-down in the Open dialog to select “All Files” since the Web Data file does not have an extension. And be sure to use Task Manager to kill all msedge processes; otherwise when you attempt to Write Changes to the database, it will fail to do so.
Profile Sync
I’ve submitted a feedback ticket to Edge requesting that search engines sync as part of the profile. They accepted the ticket and put it in their backlog. I mentioned to them that Chrome does this automatically. I’m not counting on the feature getting implemented though, so I found it worth my time to find a quick solution to configure and “sync” my search engines myself.